- Home
- Various Articles - Vocabulary/ Error correction
- Using a Corpus for Post-writing Corrective Feedback on Word-choice Errors
Using a Corpus for Post-writing Corrective Feedback on Word-choice Errors
Shaun Justin Manning received his Ph.D. from Victoria University of Wellington, New Zealand. He is an associate professor in the Department of English Linguistics and Language Technology at Hankuk University of Foreign Studies, Seoul. His research interests include: EFL writing instruction and feedback, automated writing evaluation, TBLT, classroom dynamics, collaborative learning, integrated skills development, and language in use. Email: shaunmanning@yahoo.com
Abstract
The word-choice error is a challenging type of error for EFL writing teachers in that it is impossible for teachers to predict in advance, and must therefore be treated post-writing via written corrective feedback (CF). Moreover, there are often cases where the chosen word is not so much incorrect but simply ‘odd-sounding’ to the reader, making explanations for why it was flagged as incorrect unsatisfying for the learner. In addition, there is still considerable debate over the effectiveness of teacher CF on long term language acquisition: not least because students may ignore the feedback, or simply read it and not act on it. Having students rewrite their work and make the correction is an effective approach, but does not explain to the learner why the word-choice was incorrect. This paper describes a corpus-supported classroom activity that teachers can use with students to promote an understanding of the distinctions between the two words that the students had confused in their writing. Although challenging to implement the first time, it was found to be useful by the student-writers who did the activity.
Introduction
Learning to write in another language is one of the most difficult aspects of foreign language (FL) learning because writing leaves a permanent record and the audience is not present at the time of writing to ask for and receive clarification. Therefore, writing requires a level of linguistic precision not required of speech.
Because writing is an element of FL learning, writing is also used to teach FL – i.e. there are simultaneous needs for students to both learn to write and write to learn (the target language [TL]). This second goal of ‘writing-to-learn-the-TL’ requires teachers to address not only ‘writing’ concepts, such as organization, thesis statements, genre requirements, etc. but also linguistic challenges the students are having, in particular lexico-grammatical accuracy, range, and appropriacy (Bitchener & Knoch, 2010; Bitchener & Storch, 2016; Ferris, 2010).
Teachers have a range of options for addressing the language needs of their students. They can arrange the syllabus to somehow a priori teach what the students do not know, give large amounts of practice, and then let the students write. However, even with large amounts of pre-teaching, students still make linguistic errors in their writing.
Another approach, one not mutually exclusive with the above, is to give corrective feedback (CF) on the students’ writing. Corrective feedback can occur in many ways, but the most common are either directly correcting the student’s error, indicating the error at the location of the error with a code or a generic mark (e.g. underlining it), or indicating in the margin that there is an error in that line (e.g. Chandler, 2003).
However, since the late 1990’s, there has been considerable debate on the utility of CF of eliminating error from student writing (Ferris, 1999; Truscott, 1996). The debate is still ongoing, but to a large extent we know that the success of CF depends on among other things: the type of error, the attention the student pays to the error, the nature of the CF given, and the proficiency level of the student (Ferris & Hedgcock, 2014). Even though its usefulness as a language teaching tool is still open to challenge, many students (and their parents) expect teachers to indicate wherever and whenever there are errors.
Yet, even when teachers indicate the errors and have students rewrite the corrected version, some error types get made repeatedly. This can be due to L1 interference (e.g. a different word order for Korean and English), or a lack of similar structures in the writer’s L1 (e.g. the English article system is highly problematic for Korean EFL learners) – i.e. the errors are the result of systemic challenges for the learners. Although systemic issues are important, this study focuses on a more individual-student level of error: the word-choice error.
Word choice errors (also called ‘wrong word’ errors) are errors in which the word supplied by the student writer is semantically incorrect for the sentence context: e.g. ‘My mother is a housekeeper’ when the writer meant her mother was a ‘housewife’ and did not clean hotel rooms for a living. These errors are sometimes easy to identify, but can often be challenging, because, as in the example above, the word ‘housekeeper’ is correct if the writer’s mother were indeed employed as a housekeeper. In addition, the actual error may be elsewhere in the sentence (especially when dealing with concepts such as borrow and lend etc.). However, for this study, errors were considered word choice errors if (a) changing that one word made that part of the sentence semantically and grammatically correct, and (b) if the revision made the sentence true – which necessitates confirming with the student what their intention was. This means that identifying and correcting word choice errors is actually a collaborative effort between teacher and student. This current report extends this collaboration into an activity in which the student searches a dictionary and a corpus (Corpus of Contemporary American English, Davies, 2008) to figure out why and how they made the error and then the student ‘teaches’ other students about their error in a small-group activity.
The use of corpora in EFL learning
Corpora, large collections of words from pre-specified genres of speech and writing have become fairly common tools for linguists, dictionary publishers, grammarians, and language teachers. One of the earliest efforts to use corpora in EFL learning was proposed by Tim Johns (Johns, 1994) with what he called ‘Data Driven Learning’. In its simplest form, DDL involved collecting corpus lines that exemplified certain uses of a word and asked students to deduce a meaning or a grammatical rule based on the evidence (the corpus lines) presented to them. In this respect, the corpus created materials for learning. The advantage was that the teacher could notice issues the students were having and create materials to help them with a few clicks of the mouse, rather than try to create new examples.
Large corpora are freely available online, one of the best sites being the Corpus of Contemporary American English (Davies, 2008) and its associated corpora. So, the DDL approach can be used simply and effectively to help address some of the systemic errors mentioned above. However, this study proposes using a corpus as one step in a process of analysis designed to: (1) address individual-level errors of word choice, and (2) to show students how they could use the corpus themselves when writing, if they were concerned about their choice of words. In short, this study proposes using a corpus to help personalize the error correction and language learning process.
The learning context and problem
The context for this intervention was a university in Seoul, South Korea where the author taught EFL writing to relatively advanced learners, with the weakest at CEFR B2 level and the highest at C1 (Council of Europe, 2001). The students were English major undergraduates attending the higher level of a two-level freshmen (first year) academic writing course. To enter the top level, students had to be in the top 40% of incoming freshmen as ranked by their scores on a pre-semester writing test. There were no international students in the class, but some students had lived abroad for several years.
Despite their strength at writing, students still made several word-choice errors on each writing assignment submitted. Some common examples from the author’s classes included:
- Make vs. let: where the students do not reflect the degree of imposition / permission
- Borrow vs. lend: where there is an issue of deixis and the students’ L1 has same basic verb, billida, for both actions – albeit conjugated differently
- Play with vs. use a computer: their L1 verb nolda (to play) has a wider semantic field than the English equivalent.
Some less common, but interesting examples include:
- People vs. humans: where the TL is semantically very similar and word-choice errors can only be identified by the semantic field (social contexts vs. scientific contexts)
- Blame vs. accuse: where the TL is semantically very similar and word-choice errors can only be identified by the collocates (e.g. accident vs. crime) or other contextual clues.
- Prostitute vs. prosecutor: where the TL is structurally similar and from the same semantic field.
- Perimeter vs. parameter: again, there is TL similarity, both structural and an overlapping semantic meaning.
The corpus investigation that I outline below is helpful in dealing with cases similar to examples 4 through 7. These are TL words that are either closely related semantically (examples 4 and 5) or both semantically and structurally (examples 6 and 7). This type of mistaken word choice often happens to South Korean writers in particular because South Korean high school students often study vocabulary by memorizing lists of words which are often arranged either by topic or alphabetised or perhaps by both, so examples 4 through 7 may well have been learned incorrectly due to the mode of presentation during learning – similar words presented together resulting in confusion, not learning. For a discussion of this issue in relation to phrasal verbs, see Strong and Boers (2019).
The basic question that this small-scale action-research project set out to address was: How can a corpus be used by students to investigate the source of their own confusion in the use of easily confused English words?
The intervention: Using the corpus
This intervention is conducted during class time, after the students’ work has been returned to them. They have already been shown how to search the Corpus of Contemporary American English (Davies, 2008).
- Teacher locates the error and codes it
- Students choose 1 or 2 WC errors to explore
- Students examine dictionary definitions of each noun
- Students make corpus searches:
- Incorrect Verb + noun
- Recommended Verb + noun
- Top 25 verb collocates with incorrect noun
- Top 25 verb collocates with recommended noun
- Examine overlapping verbs in the context of each noun
- Present finding (to their group)
I must point out that because the example below is about a noun error, this is written as Verb+Noun, but if the error were with a different part of speech, students would be directed to look for the appropriate item.
One case: define+perimeters vs define+parameters
In this section, I present a recent case of a word-choice error that can be considered ‘awkward’ more than ‘incorrect’. The purpose is to illustrate the steps. In the section that follows this, the results of observation and interviews are presented along with a discussion. Here, I exemplify for the reader, the process. The student-writer whose work is described here is a female, Jane is her pseudonym, and she had lived for over 5 years in the USA before returning to South Korea to complete her secondary and to begin her post-secondary education. Her CEFR English level is C1.
1.Teacher locates the error and signals the error
As the course instructor, I had a policy for the first few essays of the semester to correct all student errors. Later in the semester, this switched to underlining only. This lesson followed the first essay, and therefore had all errors directly corrected.
The student writer had written: “Modern society redefines the perimeters of being a man,” which I corrected to read: “Modern society redefines the parameters of being a man.” I fully recognize that other possible corrections could be made here, for example: “Modern society [extends / changes] the [perimeter / boundaries/ definition] of being a man.” I always opt for the simplest change. In doing so, I have determined that the verb ‘define’ was a correct choice and the student needs to examine the nouns that go with it. The student sees my strike through of ‘perimeters’ and my correction, ‘parameters’.
2.Students choose 1 or 2 WC errors to explore
In some students’ writing there are many WC errors, but for Jane there were only a few. In this lesson she chose to examine the difference between ‘perimeters’ and ‘parameters’ of something. So, to begin, she went online to an English dictionary and copied out the definitions she found. The process of exploration starts with an investigation of similarities and differences in meanings.
3.Dictionary search
Jane used Dictionary.com (www.dictionary.com) and found the following definitions of ‘perimeter’ and ‘parameter.
Perimeter (noun)
- the border or outer boundary of a two-dimensional figure.
- the length of such a boundary.
- a line bounding or marking off an area.
- the outermost limits.
- Military. a fortified boundary that protects a troop position.
- Ophthalmology. an instrument for determining the peripheral field of vision. (“perimeter,” 2019)
Parameter (noun)
- Mathematics.
- a constant or variable term in a function that determines the specific form of the function but not its general nature, as a in f(x) = ax, where a determines only the slope of the line described by f(x).
- one of the independent variables in a set of parametric equations.
- Statistics. a variable entering into the mathematical form of any distribution such that the possible values of the variable correspond to different distributions.
- Computers. a variable that must be given a specific value during the execution of a program or of a procedure within a program.
- Usually parameters. limits or boundaries; guidelines: the basic parameters of our foreign policy.
- characteristic or factor; aspect; element: a useful parameter for judging long-term success.
(“parameter,” 2019)
In general, students identify similarities and differences in the words’ meanings to determine both the source of their own confusion (the similarity) and any key differences at play in the sentence they wrote. Jane noted that both words could sometimes be defined as boundaries or limits. The definition of ‘perimeter’ explicitly focused on limits and boundaries in definitions 1, 2, 3, and 4. Definition 5 does not explicate limit, but a field (i.e. a field of grass or corn, etc.) has a physical boundary, so a ‘field of vision’ – a metaphorical extension of a physical field also entails a boundary or limit of what can be seen. In contrast, only one definition of ‘parameter’ uses the words ‘limit’ or ‘boundary’ – definition 4. This is the source of the student’s confusion. She felt that it was okay to use ‘perimeters’ in her mind, the limits of being a man are being changed by modern society. This is a reasonable interpretation when written as ‘limits’ and ‘changed’, but the problem lies in the combination of the words she did use: ‘define’ and ‘perimeter’. The word ‘define’ is not normally used with ‘perimeter’, in part, because it predictably goes with another word that can mean limit: ‘parameter’. To figure out why ‘parameter’ but not ‘perimeter’ can be used here, she needed to turn to a corpus.
4.Corpus searches
- Overall frequency
The student used the Corpus of Contemporary American English (Davies, 2008) to investigate the two words. Jane found that the overall frequency of ‘parameter’ was 8139 uses in the 560-million-word corpus, whereas ‘perimeter’ occurred 4526 times – just over half as frequent. Moreover, ‘parameter is the 2540th most frequent word of English, while ‘perimeter’ is 8881st. So, ‘parameter is the more common word of the two.
- Collocations of the particular words chosen
She then looked into the collocation, or co-occurrence of both sets of Verb+Noun combinations. When doing the search, she was told to investigate the words’ co-occurrence in the order written define à perimeter, and not perimeter à define. And to set the left limit at 4 words, allowing for n-grams of up to four words in length: ‘define (+ word + word) + perimeter’ and ‘define (+ word + word) + parameter. This is an arbitrary decision by the instructor in an attempt to keep the activity simpler and not introduce potential ordering effects on the meanings of the expressions the students were investigating.
Once the searches have been done, the students are encouraged to take a screenshot of them and try to look for patterns. At this stage, they can confer with partners, by exchanging their laptops (or phones) and asking their partner to substitute a synonym into some of the lines from the corpus or to try to match each line with a definition from the dictionary. The teacher moves from group to group to help, and to make sure all students both help others and get help.
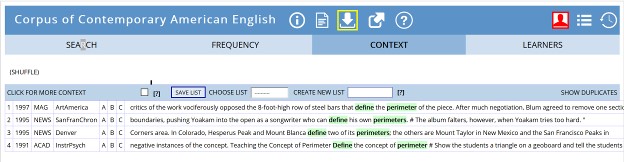
Figure 1 is a screenshot of the COCA data for ‘define + perimeter*’. The students talk about it and realize that there were only four instances of ‘define’ preceding ‘perimeter’ in the entire corpus and one of them (Figure 1, line 1) was referring to a physical perimeter of a steel cage, another (Fig 1, line 3) is describing the area bounded by four mountain peaks, and another (Fig 1, line 4) is explaining how to define a mathematical perimeter for geometry students. Only one (Fig 1, line 2) is referring to a metaphorical limit. So, in 560 million words, there is one case that matches the student’s use of ‘define + perimeter’ to refer to a metaphorical limit. At this point the student realized that she was not correct, and wanted to know more about why.
Figure 1. Sample of COCA lines for ‘define + perimeter*’ (Davies, 2008)
- Collocation patterns of the teacher’s suggestion
The investigation continues with the student looking at the teacher’s suggested correction. Figure 2 shows 22 of the 43 instances of ‘define + parameter. Among the 43 cases, nine meet definitions 1-3 above – i.e. the parameters are scientific variables of some sort (“parameter”, 2019, definitions 1-3). Twenty-four lines refer to aspects, characteristics, or factors (“parameter”, 2019, definition 5), and nine refer to limits, boundaries, or guidelines (“parameter”, 2019, def. 4). For example: Fig 2, line 2 reads, “…the evaluation did not properly structure, include, or clearly define the sensitivity analysis parameters.” Here ‘parameters’ refers to a scientific concept. Fig 2, line 1 reads: “…a cloud storage provider’s terms of service agreement can define the precise parameters of what may be disclosed to a third party.” ‘Parameters’ here is synonymous with ‘guidelines.’ Finally, Fig 2, line 4 reads, “… the midlife crisis are marked by a preoccupation with trying to define its chronological parameters …” ‘Parameters’ here are ‘characteristics’, and this is closest in meaning to its use in the student’s writing: “the parameters of being a man.”
Figure 2. Sample of COCA lines for 'define the parameter*' (Davies, 2008)
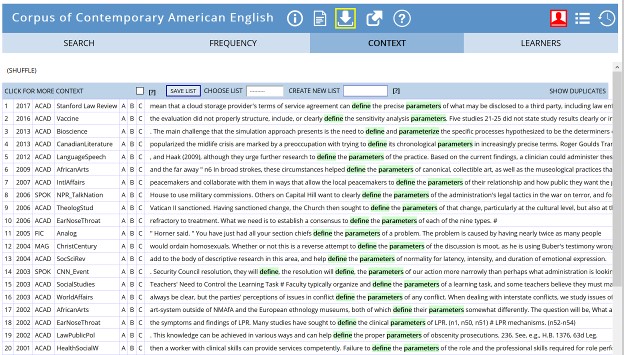
So, the student can now make a claim that when closely following the word ‘define’, the most common synonym of ‘parameter is ‘aspect / characteristic’ at a rate nearly three times higher than ‘limit’ or ‘boundary’. She also realized that what she had meant when writing was not really a limit but a set of characteristics: “Modern society redefines the perimeters (set of characteristics) of being a man.” So, by looking at the collocation pattern and the dictionary definitions, she has figured out why the instructor had felt her writing was not right.
- Searching for potential collocates
To expand the students’ knowledge of the collocates of the noun, while they are still interested in their own mistakes, teachers can continue this activity with two more corpus searches – searching for correct collocates first with the noun the student used and second with the noun the teacher recommended. I suggest limiting this to the top 20 or 25.
Figure 3. Top 25 Verbs that collocate before ‘perimeter*’ (COCA, Davies, 2008)
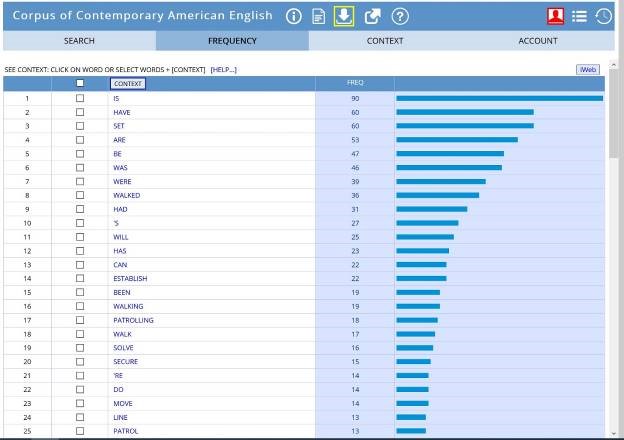
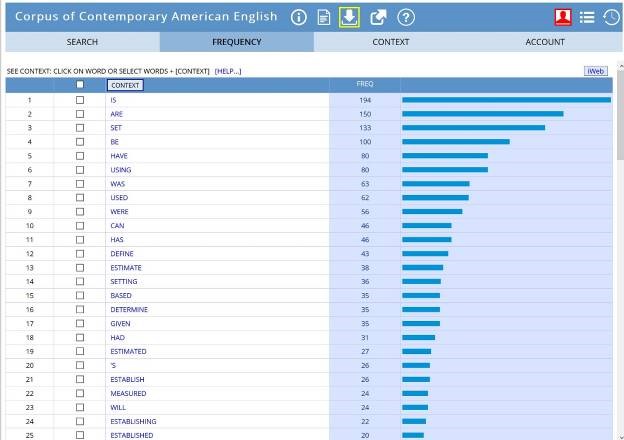
Figures 3 and 4 show the results of the corpus searches. The student immediately noticed that there is a lot of overlap – not surprisingly, ‘be’ and ‘have’ appear near the top of both lists. ‘Perimeter’ collocates with concrete actions: ‘establish’, ‘walk’, ‘secure’, ‘solve’, ‘patrol’, and ‘move’. The student realized that many of these require a physical boundary (e.g. walk (around) a perimeter). She also noted that ‘parameter collocates with some verbs that could be physical (e.g. ‘set’, ‘use’, ‘base’, ‘measure’), many are related to abstract concepts such as knowledge: ‘use’, ‘define’, ‘estimate’, ‘determine’, and ‘establish’. One thing jumps out, though. The word she had used in her essay, ‘define’ collocates only with ‘parameter and not with ‘perimeter’. So, this led her to the conclusion that she should have written “redefines the parameters.”
Figure 4. Top 25 Verbs that collocate before 'parameter*' (COCA, Davies, 2008)
5.Present findings
The final stage of the lesson is to have the students present their findings. This class was only two hours, so there was insufficient time. I had to spread the activity over two lessons. The next lesson each student had to present their findings to others in small groups (three or four students per group) and receive feedback and questions. Then the group leader had to present all the words to the class. Following the presentations, the teacher led a plenary to make sure nothing incorrect had been taught.
This is not the only way of following up the activity. While the students were teaching each other in small groups, I thought I should have done a ‘poster carousel’ activity in which half of the students move from poster to poster and the other half remain at their poster and present their findings repeatedly. Roles would be switched after each person had visited all the posters (cf. Lynch & Maclean, 2001). It is also possible to make a blended assignment. The teacher could have students create a PowerPoint presentation including screenshots of the corpus data; then record a voice-over explanation for it; and export it as a video. The video could then be uploaded to the course’s learner management system (LMS) for others to view and provide peer feedback.
Findings and Discussion of observation and interview data
A lesson following this format was done in the spring of 2019 with author as the instructor. Students regularly bring their laptop computers to class, but this week they were given a message explicitly asking them to do so. All did. Please note that the COCA can be used with smartphones if students prefer.
When the students entered class, the teacher gave each of them their essay grades, comments, and corrective feedback. Students were instructed to read the essay aloud to themselves (softly), and to read the teacher’s corrections that were made as they read their papers.
Having read their papers, students were allowed to ask the teacher about certain items, but not about word choice errors. The teacher told the students to pick two errors of word choice (vocabulary) they had made and be able to explain, in detail, why the teacher had made the changes. At first, it was observed that the students were somewhat confused and said, “Isn’t it wrong just because it is wrong?” I replied, “Of course it’s wrong, I marked it. I want you to be able to tell your partners why it is wrong, what confused you, and what might confuse them if they do not listen to you. At the end of today’s lesson, you should be able to explain the different uses and meanings of the two words you confused.”
Choosing which word choice errors to investigate was challenging for them at first. I had to ask many individuals as I moved around the room, “What is the difference between this (pointing to a word choice error) and this (my correction)?” Usually, the students could not explain it to me, understandably, they had made the error. So, I would say, “This is one you should investigate.”
The students’ dictionary searches often led to slightly overlapping meanings, as in Jane’s example above. More interestingly for me, their teacher, was to hear them challenge my corrections. One student asked: “Why can’t I write, ‘Childhood obesity is especially fatal* in* growing up?’” I had switched fatal for harmful and in for when. My answer was: “If it’s fatal, the child is dead, and not growing up.” She chose to investigate fatal, harmful, and deadly. It is precisely this type of question the activity aims to teach students how to answer for themselves. Using their own errors as a springboard into the corpus activity generated the interest and motivation necessary for the work to be done. Requiring a public presentation of their findings ensured the work was done to a high standard (Willis & Willis, 2007).
During the class, many students anecdotally commented on the difficulty of figuring out how to explain the difference between the words. They could see, particularly from the corpus collocation data that the items differed, but expressing it was challenging for them. During the presentations, there were many debates about the meanings and the accuracy of the speaker’s conclusions. This talk about language (using the TL for the most part) has been shown to be beneficial to language learning (Swain, 2010; Swain, Lapkin, Knouzi, Suzuki, & Brooks, 2009). While some of the group members negotiate what separates the pair (or triad) of words under discussion, all learn, even those who only listen to what is being said (Newton, 2013). So, placing students into a situation where they talk about specific items of language that gave them problems provides a good opportunity to expand their existing knowledge along with their capacity to investigate and explain their findings.
After class, seven students were invited to comment informally to the professor (me) about the activity. They were assured that their comments would be taken as good faith attempts to make our lessons more useful, and they could feel free to complain, criticize, or suggest changes to the activity that they felt would make it a better use of their time.
Overall, they all felt it had good potential to be helpful. They reported that they got confused when they read the corpus lines – sometimes they were too linguistically difficult or referred to cultural phenomena that the students did not understand, problems mentioned elsewhere (e.g. Hunston, 2010; Tan, 2002). They wanted more in-class assistance from the professor, but even with only twenty students, the teacher cannot be everywhere. Moreover, the focus on coming up with their own explanation requires that the instructor not get too involved. When asked if I should have let teams do the work rather then working on their own errors, they replied that it would be okay, but if the errors were presented as ‘general’ or ‘common’ errors. One student said, “I really don’t want the others to see my mistakes. I know it’s to help me get better, but it’s embarrassed (sic).” There is a real threat to their self-esteem if their errors are seen by others. So, teachers interested in trying this activity, might wish to make an anonymized list of several word choice errors and their corrections and let groups of students collaborate to explain them. If all groups worked on the same errors it would obviate the need for the presentation phase. However, because the students reported liking hearing how others explained the problems, and given the language learning benefits of talking about language, I do not suggest dropping this part of the activity. It might be preferable to give different lists to different groups, depending on the word-choice problems that arise on each assignment.
Implications and final comments
I focused this activity to supplement the teacher’s CF on word choice errors. I did this because I felt that the combination of dictionary and corpus might highlight why they had felt their original choice was better and why my (the teacher’s) correction was chosen. It is possible to look for other features using the corpus, but when the differences are minor and cannot be explained easily the dictionary phase may be unhelpful and the corpus data too overlapping to help. An approach closer to the original DDL in which the teacher selects the corpus lines for the students to explore may be more helpful. However, in the case of word choices, particularly nouns or verbs, which, although may have near synonyms, the collocates will differ and this will highlight the differences in meaning and use. In these instances, the dictionary-corpus approach may be helpful.
This activity provides another way of directing attention to learner error while also providing a means for students to investigate language questions they may have on their own. As such, it develops learner autonomy. It does however, require extensive involvement from the teacher in advance to teach students how to use the corpus and during class to aid in selecting which errors to focus on, and in providing hints as to which collocates to investigate with the item in the WC error.
Also, the Corpus of Contemporary American English is free for individuals to use, but your institution should purchase an institutional account if you are considering making this activity a regular part of your class. There are other online corpora available, and the internet itself is a corpus – however one with millions of what might be best called ‘examples of questionable language’ (e.g. “Your an idiot,” etc.). It has been suggested that Google Scholar (https://scholar.google.com/) might be a useful choice as a corpus (Swales & Feak, 2012), presumably because its contents are peer reviewed articles, and therefore for the most part, grammatically accurate and of an academic register. The point, however, is that using a corpus that contains ‘proofed’ samples of language can be a helpful way for students to examine the underlying confusions that lead to errors in word choice. Teachers will probably not have time to do this activity often, but as mentioned above, students felt they learned from it, not just about the language items, but about how to go about learning. The complexity of the task seems worth the effort, at least for classrooms with students of similar proficiency and motivation as the participants here.
Funding note
This research was supported by the Hankuk University of Foreign Studies Research Fund, 2019.
References
Bitchener, J., & Knoch, U. (2010). The Contribution of Written Corrective Feedback to Language Development: A Ten Month Investigation. Applied Linguistics, 31(2), 193–214. https://doi.org/10.1093/applin/amp016
Bitchener, J., & Storch, N. (2016). Written corrective feedback for L2 development. Toronto, ON: Multilingual Matters.
Chandler, J. (2003). The efficacy of various kinds of error feedback for improvement in the accuracy and fluency of L2 student writing. Journal of Second Language Writing, 12(3), 267–296. https://doi.org/10.1016/S1060-3743(03)00038-9
Council of Europe. (2001). Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Cambridge: Cambridge University Press.
Davies, M. (2008). The Corpus of Contemporary American English (COCA): 560 million words, 1990-present. Retrieved May 31, 2019, from COCA website: https://www.english-corpora.org/coca/
Definition of parameter | Dictionary.com. (2019). Retrieved August 31, 2019, from Www.dictionary.com website: https://www.dictionary.com/browse/parameter
Definition of perimeter | Dictionary.com. (2019). Retrieved August 31, 2019, from Www.dictionary.com website: https://www.dictionary.com/browse/perimeter
Ferris, D. R. (1999). The case for grammar correction in L2 writing classes: A response to truscott (1996). Journal of Second Language Writing, 8(1), 1–11. https://doi.org/10.1016/S1060-3743(99)80110-6
Ferris, D. R. (2010). Second Language Writing Research and Written Corrective Feedback in SLA. Studies in Second Language Acquisition, 32(02), 181–201. https://doi.org/10.1017/S0272263109990490
Ferris, D. R., & Hedgcock, J. (2014). Response to student writing: Issues and options for giving and facilitating feedback. In Teaching L2 composition: Purpose, process, and practice. NY: Routledge.
Hunston, S. (2010). Corpora in applied linguistics (7. print). Cambridge: Cambridge Univ. Press.
Johns, T. (1994). From printout to handout: Grammar and vocabulary teaching in the context of Data-driven Learning. In T. Odlin (Ed.), Perspectives on pedagogical grammar (p. 293). Cambridge ; New York, NY, USA: Cambridge University Press.
Lynch, T., & Maclean, J. (2001). “A Case of Exercising: Effects of immediate task repetition on learners” performance. In Martin Bygate, P. Skehan, & M. Swain (Eds.), Researching Pedagogic Tasks: Second Language Learning, Teaching and Testing (pp. 141–162). Harlow, England: Pearson Education Ltd.
Newton, J. (2013). Incidental vocabulary learning in classroom communication tasks. Language Teaching Research, 17(2), 164–187. https://doi.org/10.1177/1362168812460814
Strong, B., & Boers, F. (2019). The Error in Trial and Error: Exercises on Phrasal Verbs. TESOL Quarterly, 53(2), 289–319. https://doi.org/10.1002/tesq.478
Swain, M. (2010). “Talking-it-through”: Languaging as a source of learning. In H. Byrnes (Ed.), Sociocognitive Perspectives on Language Use and Language Meaning (pp. 112–130). Oxford / New York: Oxford University Press.
Swain, M., Lapkin, S., Knouzi, I., Suzuki, W., & Brooks, L. (2009). Languaging: University Students Learn the Grammatical Concept of Voice in French. The Modern Language Journal, 93, 5–29.
Swales, J. M., & Feak, C. B. (2012). Academic Writing for Graduate Students: Essential skills and tasks. Ann Arbor, [Mich.]: University of Michigan Press.
Tan, M. (2002). Corpus studies in language education. Huamark, Bangkok: Iele Press.
Truscott, J. (1996). The Case Against Grammar Correction in L2 Writing Classes. Language Learning, 46(2), 327–369.
Willis, J., & Willis, D. (2007). Doing Task-Based Teaching. Oxford: Oxford University Press.
Please check the Advanced Level English Update for Teachers course at Pilgrims website.
Please check the Creative Methodology for Using ICT in the English Classroom at Pilgrims website.
Please check the Teaching Advanced Students course at Pilgrims website.
Using a Corpus for Post-writing Corrective Feedback on Word-choice Errors
Shaun Justin Manning, South Korea