- Home
- Various Articles - Teaching Adults/Advanced
- An Analysis of Parallel Forms of the English Language Entrance Test
An Analysis of Parallel Forms of the English Language Entrance Test
Pavel Svoboda is a lecturer of English at the University of Defence in Brno, Czech Republic. Currently, he is working as an English tester at the Testing Department of the University of Defence and he focuses on the theory of language testing, the practice of test development and statistical test analysis. Email: pavel.svoboda@unob.cz
Daniel Lawrence Schneiter has been a teacher of English language for over ten years in the Czech Republic. He has teaching experience from a wide range of educational institutions as well as corporate entities. Currently, he is working as an English tester at the Testing Department of the University of Defence.
Abstract
This article deals with the challenges of development of an English language entrance test at the University of Defence in Brno, Czech Republic. This kind of test is considered to be a high-stakes test and it is part of a battery of tests which should serve the purpose of “sieving” the candidates desiring to study at the University. The format and content of the English language entrance test is designed in a way to reflect the target language needs of the students and the English language proficiency requirements the students have to meet during or at the end of their studies. Development of the entrance test is a cyclic and continuous process annually requiring extensive human and time resources, which brings about the question of how to check the quality and how to achieve efficiency of such a process. For this purpose, the authors of the paper decided to examine the results of this test with the prime focus on the analysis of individual parallel forms of the test, which are necessary to be developed due to the testing conditions and background at the University.
Introduction
The process of test development is a complex effort with multiple aspects that can be emphasised or focussed on depending on the importance, the purpose or the testing environment in which this process takes place. The two traditional characteristics of high-quality tests are considered to be validity and reliability ensuring that the particular test provides desirable results. When the test development process involves the necessity to develop more versions of a test providing the same desirable results on all testing occasions, other test characteristics may come to the forefront to interplay with validity and reliability. Two of these are test fairness and practicality.
Davies et al. (1999) distinguishes two types of test fairness – fairness at the test construction stage and at the test administration stage. While fairness at the test construction stage is more or less connected with the effort to choose the test content in an unbiased way towards any target group, fairness at the administration stage should “ensure that the conditions under which the test is administered are constant across candidates and testing occasions” (p. 200). In this context, Davies also considers tests with objectively-scored items fairer to candidates than those with subjectively-scored items and he sees this latter type of fairness synonymous with reliability.
Test fairness in the broader sense can therefore be considered as the same and equal treatment of all candidates during the administration stage, irrespective of any differences in their cultural background, age, gender or the testing conditions. The last aspect gains its importance when the testing situation requires using various versions of the same test, because the number of the candidates is so high that a single administration of the test would be demanding technically and consecutive administration of the same version of the test on multiple occasions would compromise the test. In that case, even if all personal traits of the candidates were catered for in a fair way, just the simple fact that one version of the same test might be more difficult than other versions would disadvantage unfairly those candidates taking this particular version of the test. That is why test fairness in this context calls for developing equal versions of the test having the same characteristics.
As for practicality of the test, it means considering a certain amount of compromise between validity and reliability of the test, on the one hand, and the extent to which using the test in a specific testing situation is really practical, on the other hand. That is to say a test with high validity and reliability takes a long time and a lot of effort to develop, and the ideal form of the test might be so complex that the development and administration of such a test would be highly impractical. For Davies et al. (1999), the term practicality covers a range of issues, like the cost of development, test length, ease of marking, time required to administer the test, ease of administration or the availability of appropriate rooms or equipment. If there is a need to develop multiple versions of the same test, this practicality aspect of the test becomes even more significant and it is advisable to resort to a manageable format of the test.
Developing different versions of a test, which ideally provide very similar results, is a big challenge for the test developers and various approaches might be taken in this respect. In the testing literature, there are basically three terms used for these versions of a test – parallel, alternate or equivalent – with slight differences in their meaning. According to Alderson (1995), parallel tests “are designed to be as similar to each other as possible. They should, therefore, include the same instructions, response types and number of items, and should be based on the same content. They should also, if tried out on the same students, produce the same means and standard deviations.” (p. 96). Alderson points out that constructing such parallel tests is very difficult and sometimes equivalent tests are produced instead, which “are based on the same specifications, but which may vary as to the number of items, the response types and the content” (p. 97). It means that the equivalent tests might not look identical in their format, when compared with the parallel tests. Alternate tests, in contrast, are required to look identical from the formal point of view, however, they are not always required to demonstrate the same statistical characteristics (Davies at al., 1999).
Research objectives and methods
At the University of Defence (UoD) in Brno, Czech Republic, one of the authors of this paper is responsible for the development of an annual English language entrance test which is considered to be a high-stakes test and is intended to examine the candidates’ general English language proficiency at approximately a B1 level according to the Common European Framework of Reference (CEFR). This is the minimum English language proficiency level that the students at the UoD are required to achieve by the end of their studies. As the test is of significant importance and the development of such a test is highly demanding from the point of view of time and human resources, the authors were logically interested in examining the test quality and possible ways of making the test development process more efficient. To this purpose, the authors have decided to carry out a statistical analysis of the English language entrance test results from two previous years, examining them from the perspective of test fairness and practicality.
The format of the entrance test includes two subtests of two language skills – listening comprehension and reading comprehension. The listening subtest consists of 20 multiple-choice items in the form of monologues or dialogues from everyday life with a total maximum length of 25 minutes. Each recording is repeated and the max. number of points awarded for this subtest is 20. The reading subtest also consists of 20 items, but the items are of three different types to cover the reading skills more thoroughly. The first subpart includes 10 multiple-choice items with paragraph-length texts dealing with everyday topics. Each of these items is awarded two points because this activity involves reading in detail. The second subpart is represented by an article which is approximately 25 lines and its summary is a five-line text where there are five gaps, each for filling in one word logically completing the summary. The max. number of points awarded for the summary is 5. The third subpart contains another article with five open-ended questions that should be answered with the max. of four words. Altogether, these questions are awarded the max. number of 5 points. The articles in the last two subparts typically deal with rather technical or specialized topics that might be of interest to the target group of UoD students. The max. number of points awarded for the reading subtest is 30. The format of the entrance test is summarized in Figure 1.
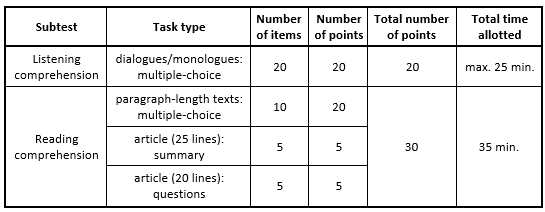
The entrance test with this format is administered at two faculties of the UoD in Brno – the Faculty of Military Leadership (FML) and the Faculty of Military Technology (FMT). Due to the high number of applicants being tested (approx. 400 every year), the testing conditions at the UoD necessitate dividing the testing sessions into several days – one week at the FML and another one at the FMT. As a result, it would be impossible to administer the same version of the entrance test on all these testing occasions without compromising the test. That is why it is necessary to annually develop several versions of the test to achieve the desired validity of the test results. This necessity, however, brings about the issue of test fairness and test practicality, because each version of the test should have the same characteristics and behave in the same way to treat all the applicants fairly. The development of all the test versions should also be manageable from the point of view of time, human resources and administration requirements to consider the entrance test to be truly practical.
Ensuring test fairness in the sense of treating all the test-takers in the same way requires having parallel forms of the entrance test, which are very difficult to develop. Bachman’s (1990) operational definition of parallel tests is that “parallel tests are two tests of the same ability that have the same means and variances and are equally correlated with other tests of that ability” (p. 168). This concept of parallel tests assumes that the tests are administered to the same group of individuals, which is impossible in a real-life testing environment and, for obvious reasons, it was not the case with the entrance test at the UoD. That is to say, the entrance test versions were administered to different groups of test-takers and in order to be able to analyse the results of these test versions, the authors made the essential assumption that the language proficiency of all these individuals was equally distributed and on the same overall level in all the tested groups, otherwise biased results would be obtained. As for correlating the scores from parallel test forms, which actually means assessing parallel-form reliability, the assumption of equal distribution of the language proficiency across the tested groups is not possible in this case because the essential prerequisite of the correlation analysis is to correlate data obtained from the same group of individuals. As in practice, it is often the case that it is not possible to administer more versions of a test to the same group of test-takers, the correlation analysis is usually not available and Bachman (1990) accepts that “we treat two tests as if they were parallel if the differences between their means and variances are not statistically significant” (p. 168). The authors of this paper decided to take this approach and analysed the above-mentioned test characteristics by using appropriate tests of significance, namely the F-test for variances (standard deviations) and the Student’s t-test for means (the difficulty level).
As for the practicality of the English language entrance test, the authors considered the possible ways of making the test more practical and one of the options seems to be the reduction of the test format to only one subtest, namely of the language skill of reading comprehension, thus preferably discarding the subtest of listening comprehension which is very time-consuming to develop and demanding technically to administer. This reduction, however, could only be justified on the condition that both of these subtests provided very similar results and that, consequently, merely one of them would provide sufficient information about the test-takers’ language proficiency on the basis of which appropriate decisions could be made. This approach to various forms of a test is close to Alderson’s (1995) concept of equivalent tests mentioned in the Introduction of this paper. Alderson also points out that “what is important with equivalent tests is that they each measure the same language skills and that they correlate highly with one another” (p. 97). Unfortunately, in analyzing the two subtests of the entrance test, the first condition could not be met, however, having the same group of individuals taking both subtests enabled application of the correlation analysis, so the correlation coefficient r was calculated and its significance was examined.
Research findings and interpretation
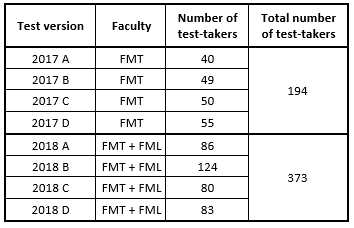
In order to analyse whether the parallel forms of the English entrance test at the UoD can really be considered “parallel” and whether the subtest of listening comprehension can be justifiably discarded from the entrance test, the authors of the paper analysed the scores of all the test-takers that were available. Altogether, they managed to obtain the test results for the years 2017 and 2018. For the year 2017, the results were available only for one faculty (the FMT) and for the year 2018, the results for both faculties were available (the FMT and the FML). For both years, four alternative tests were developed (test versions A, B, C and D), each test consisting of the listening comprehension subtest and the reading comprehension subtest. Due to time and human resources constraints, only about two thirds of all the items for the particular test were produced completely new and one third of the items were recycled from the previous years. Some extent of continuity was achieved in this way. All newly developed items were pretested on a group of individuals, ideally having personal characteristics and language proficiency similar to the target group of test-takers (i.e. approximately level B1 according to CEFR). The results of this pretesting phase were analysed and statistical characteristics of the items were determined. Based on these parameters, like the item facility value (i.e. item difficulty) or the item discrimination index (i.e. the item’s ability to differentiate between high and low scoring test-takers), the items were combined in a way to even out any differences in these parameters with the effort to compile test versions ideally showing similar statistical characteristics. The numbers of test-takers whose scores were analysed for each individual test version are shown in the following Figure 2.
The authors of this paper were interested in the standard deviations of all the test versions and their difficulty level because on the basis of an analytical comparison of these statistics, the conclusion about “parallelness” of the tests could be reached. To compare the means of the test versions, the Student’s t-test was used which assumes that there is no significant difference between the standard deviations of the tests. To examine compliance with this condition first, the F-test was applied to all pairs of the test versions and for the significance level α = 0.05, the following p-values in Figure 3 were obtained.
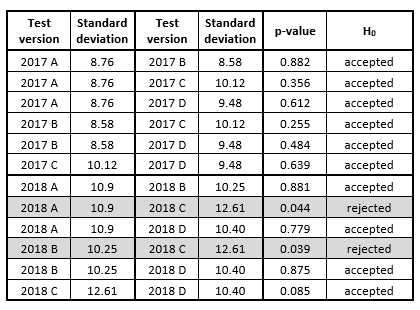
It can be seen that for most of the test versions the p-values exceeded the significance level α = 0.05, which means that the difference between the standard deviations of the pairs of tests is not big enough to be statistically significant and, consequently, the null hypothesis (H0) can be accepted. Only in two cases, when the test versions 2018 A and 2018 C, and the test versions 2018 B and 2018 C were compared, the difference between their standard deviations was statistically significant, but after applying the significance level α = 0.01, even in these cases the p-values exceeded the significance level. Thus, the final conclusion that can be made is that variances in all the test versions are the same which proves that all the test score samples were obtained from the same population. Consequently, this fact justifies the application of the Student’s t-test to examine whether the means of the test versions are statistically also the same.
When performing the Student’s t-test, the experimental texp value is calculated on the basis of the two means obtained for the two compared tests and this texp value is compared with the critical (theoretical) tth value corresponding to the given degrees of freedom of the two tests and the confidence level chosen. If texp>tth then H0 is rejected, otherwise H0 is accepted. Critical tth values can be found in statistical tables, but nowadays, statistical analysis programs are used instead which provide such calculations. The authors of the paper decided to use one of these applets available online (see the References) which calculated the value P showing the probability of Type 1 error (erroneous rejection of H0 even though it is true). This applet also provided results for the predefined confidence levels (CL) of 90%, 95% and 99% expressing the certainty with which H0 can be accepted (A) or rejected (R). The results of the Student’s t-test are shown in the following Figure 4.
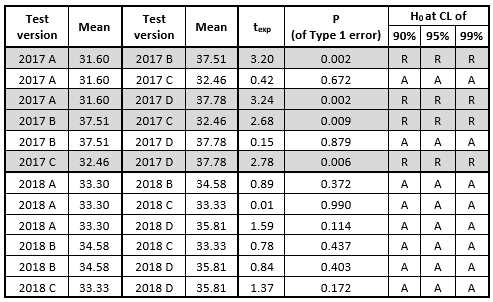
Based on the results of the analysis, it can be said that in the year 2018, the individual test versions were much more balanced as for their difficulty level than the test versions in the previous year because their means were statistically the same and, consequently, these test versions could really be called “parallel tests”. On the contrary, the test versions in the year 2017 showed greater variability in their difficulty level caused either by less prior experience of the test developer or by the mere fact that there were fewer test-takers available that year to provide a larger sample for the analysis (see Fig. 1), which might have possibly resulted in distorting values of the means of the particular test versions.
To justify discarding the subtest of listening comprehension from the entrance test and thus making it more practical, the authors of the paper needed to analyse the correlation between the two subtests of each test version and to submit the obtained correlation coefficients to the appropriate test of significance. The results of the correlation analysis are provided in the following Figure 5.
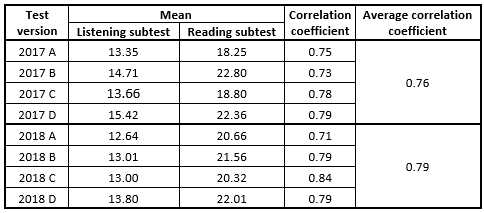
 It is obvious from the results that for the test versions from the year 2017 there was greater variability in the means of the subtests than in the means of the subtests from the year 2018. This greater variability might be accounted for by the lower number of the tests from the year 2017 available for the analysis (like in Fig. 4) or by the limited experience of the test developer to balance the means more evenly in the individual test versions. Particularly in the subtest of reading comprehension, this imbalance is rather conspicuous, which might also be attributed to the fact that this subtest is time limited and the slower reading test-takers may not have completed it, thus possibly losing some points. Nevertheless, all values of the correlation coefficients between the subtests are high and suggesting a strong relationship between the subtests. To test the statistical significance of the individual correlation coefficients, it is possible to use the test statistic t of the Student’s t-distribution which is calculated by using the formula
It is obvious from the results that for the test versions from the year 2017 there was greater variability in the means of the subtests than in the means of the subtests from the year 2018. This greater variability might be accounted for by the lower number of the tests from the year 2017 available for the analysis (like in Fig. 4) or by the limited experience of the test developer to balance the means more evenly in the individual test versions. Particularly in the subtest of reading comprehension, this imbalance is rather conspicuous, which might also be attributed to the fact that this subtest is time limited and the slower reading test-takers may not have completed it, thus possibly losing some points. Nevertheless, all values of the correlation coefficients between the subtests are high and suggesting a strong relationship between the subtests. To test the statistical significance of the individual correlation coefficients, it is possible to use the test statistic t of the Student’s t-distribution which is calculated by using the formula
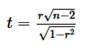
where r is the particular correlation coefficient being tested and n is the number of the compared pairs in the sample (i.e. the test version). Next, the value of the test statistic t is compared with the critical value of the Student’s t-distribution for the chosen significance level α and degrees of freedom (n – 2). This critical value can be obtained either in MS Excel by using the statistical function TINV or by means of an online statistical applet. The two-tail version of the critical statistic can be both a positive and a negative number, and these two extreme numbers delineate a critical range of values which must be exceeded by the value of the test statistic t so that the H0 (stating that the correlation coefficient is not significantly different from zero) could be rejected. The calculated values of this significance test with the significance level α = 0.01 are provided in the following Figure 6.
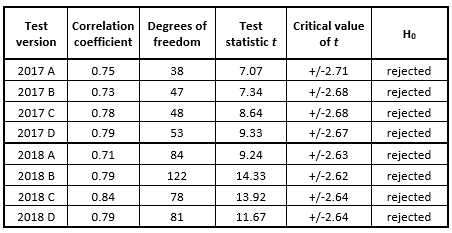
The stricter significance level α = 0.01 was chosen on purpose to increase the certainty with which the final results of the analysis could be treated. From Figure 6 it is obvious that even for this significance level the test statistic t was always safely away from the critical range of t values and, consequently, H0 could be rejected for all the test versions with the conclusion that all the correlation coefficients being tested are significantly away from zero, proving a strong and statistically significant relationship between the two subtests of all the test versions.
Conclusions and recommendations
The statistical analysis of the results of the English language entrance test at the UoD for the years 2017 and 2018 has proved that the test versions used in the year 2018 show characteristics typical of parallel tests, such as statistically insignificant variations in standard deviations and the difficulty level (i.e. means), complying with the principle of test fairness when all the test-takers should be treated in the same way, irrespective of their personal traits, and not being disadvantaged by any particular test version given to them. This “test parallelness” also proves the high quality and parallel-form reliability of the test versions developed in this way. However, the varying difficulty level of the test versions for the year 2017 (see Fig. 4) and the imbalance in the difficulty level between the individual subtests for that year (see Fig. 5) suggest that developing parallel tests is really a difficult task requiring adequate prior experience of the test developer or developers. One of the possible solutions would be making the format of the entrance test more compact by discarding one of the subtests, which would avoid the necessity to intricately combine items for two different language skills to achieve the desired test characteristics. From the perspective of test practicality, the subtest logically liable to being discarded is the subtest of listening comprehension because its development and administration poses a much higher human resources and technological challenge than the subtest of reading comprehension. The results of the provided statistical analysis of the correlation between the particular subtests also support this argument, proving that there is a strong relationship between them and the high values of the correlation coefficients to a great extent enable to predict test-takers scores from one subtest on the basis of the other subtest. This prediction, however, can never be of absolute validity because the values of the correlation coefficients do not approximate the value of 1, which is a fact expectable and desirable when comparing two different language skills having their own specific essence and idiosyncrasies. Conclusions of this paper with the suggestion to discard the subtest of listening comprehension from the English language entrance test will be submitted to the management of the UoD to make appropriate considerations, hopefully resulting in the desired decision.
References
Alderson, J. Ch. (2000). Assessing Reading. Cambridge University Press.
Alderson, J. Ch., Clapham, C, Wall, D. (1995). Language Test Construction and Evaluation. Cambridge University Press.
Bachman, L. F (1990). Fundamental Considerations in Language Testing. Oxford University Press.
Bachman, L. F. (2005). Statistical Analyses for Language Assessment. Cambridge University Press.
Buck, G. (2001). Assessing Listening. Cambridge University Press.
Davies, A., Brown, A., Elder, C., Hill, K., Lumley, T., McNamara, T. (1999). Dictionary of Language Testing. Cambridge University Press.
McNamara, T. (2000). Language Testing. Oxford University Press.
Rowntree, D. (2000). Statistics without Tears. Penguin Books.
Please check the Teaching Advanced Students course at Pilgrims website.
Motivation and Creativity for the Implementation of A New English Language Strategy, Maritza Núnez Arévalo, Ana Velia Domínguez Leó and Tania Morales de la Cruz, Cuba
Fostering Autonomous Motivation in EFL Classroom: A Self-determination Theory, Perspective, Hossein Rahmanpanah, Iran